
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Graph Embedding
- sentence BERT
- 아마존 추천시스템
- 딥러닝
- 시계열 추천시스템
- Sequential Recommendation System
- SBERT
- collaborative filtering
- Recommender System
- sentence embedding
- Sequential Recommendation
- graph
- PinSAGE
- multi modal recommendation
- side information
- 그래프 임베딩
- 시퀀셜 추천시스템
- LightGCN
- Recommendation System
- GCN
- 반복 구매
- BERT4Rec
- 머신러닝
- graph recommendation
- 추천시스템
- DIF-SR
- Multi-Modal
- 문장임베딩
- UltrGCN
- VATT
- Today
- Total
AI 공부 기록 블로그
[논문 리뷰] LightGCN: Simplifying and Powering Graph ConvolutionNetwork for Recommendation 본문
[논문 리뷰] LightGCN: Simplifying and Powering Graph ConvolutionNetwork for Recommendation
dhgudxor 2022. 1. 5. 12:30본 논문은 2020년 SIGIR conference에서 발표되었으며, 그래프를 접목한 Collaborative Filtering 방식의 추천 시스템 논문입니다. 기존의 그래프 기반 추천시스템에서 불필요한 요소들은 제거하고 추천에 필요한 요소만 사용해 가벼우면서도 좋은 추천 성능을 보인 논문입니다.
논문의 리뷰는 저의 주관적인 해석과 오역이 있을 수 있습니다. 이에 대해서 댓글 남겨주시면 감사하겠습니다. :)
1. Introduction
먼저 Collaborative Filtering(CF)은 비슷한 행동을 가진 유저들이 비슷한 아이템을 선호할 것이라는 가정으로 추천시스템에서 널리 사용되는 방법입니다. CF는 유저와 아이템 각각의 임베딩 벡터를 생성하고, 내적을 통해 유저가 선호할만한 아이템의 스코어를 계산합니다. 2019년에 등장한 "Neural Graph Collaborative Filtering(NGCF)"은 유저와 아이템 임베딩 벡터를 Embedding Propagation Layer를 통과해 각각의 임베딩 벡터를 업데이트하여 유저가 선호할만한 아이템 스코어를 계산하여 추천에 좋은 성능을 보였습니다. 하지만 본 논문의 저자들은 NGCF가 임베딩 벡터를 업데이트하는 과정(Embedding Propagation Layer)에서 Graph Convolution Network(GCN)의 구조(feature transformation, neighborhood aggregation, nonlinear activation)를 차용했다고 지적합니다. 본래 GCN의 경우 node들에 포함된 정보들을 통해 node classification의 문제를 해결하기 위해 만들어졌으며, 유저와 아이템 간의 연결성만 표현한 CF 구조에서는 적절하지 않다고 지적합니다.
2. Preliminaries
2.1 NGCF Brief
그러면 이제 NGCF 구조에서 유저와 아이템 임베딩 값들이 전달되는 Embedding Propagation Rule를 보면 아래와 같은 수식으로 표현될 수 있습니다.
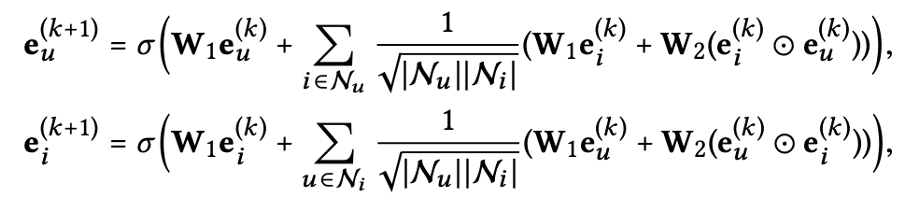
주요 특징들을 보면 self-connection ($W_1e^{(k)}_u, W_1e^{(k)}_i$)을 통해 이전에 갖고 있었던 임베딩의 정보는 유지하고, feature transformation($W_1, W_2$)과 nonlinear activation($\sigma$)를 사용해 임베딩 값을 업데이트시키는 것을 알 수 있습니다.
2.2 Empirical Explorations on NGCF
저자들은 NGCF를 실험한 같은 조건과 데이터셋에서 다음과 같은 3가지 측면에서 ablation study를 진행하였습니다. 1) NGCF-f : feature transformation matirx 제거 ($W_1, W_2$), 2) NGCF-n : non-linear activation function 제거 ($\sigma$), 3) NGCF-fn : feature transformation matirx와 non-linear activation function 둘 다 제거

위의 그림을 통해 ablation study의 결과를 보면 먼저, feature transformation matrix를 제거하였을 때 평가지표 recall@20에 대하여 기존 NGCF 모델보다 우수한 성능이 나타남을 알 수 있습니다. 반면 non-linear activation function을 제거한 경우에는 기존 NGCF 모델보다 성능이 떨어지는 것을 알 수 있지만, feature transformation matrix와 non-linear activation function을 동시에 제거하였을 때 기존의 NGCF 성능보다 훨씬 좋아지는 것을 알 수 있습니다. 이에 따라 저자는 추천시스템 모델을 구성할 때 각 요소가 어떠한 영향력을 갖는지 알 수 있게 ablation study를 하는 것이 중요하다고 강조합니다. 해당 연구를 통해 CF에 사용하기 위한 GCN의 필수 요소(neighborhood aggregation)만 포함한 LightGCN 모델을 제안합니다.
3. METHOD


위 NGCF와 LigtGCN의 아키텍처를 보면 두 모델이 공통으로 처음 임베딩 벡터$e^{(0)}_u$, $e^{(0)}_i$가 입력으로 들어옵니다. 이후 각각 서로 다른 Embedding Propagation Layers를 통과해 유저와 아이템의 연결성을 만듭니다. 이후 NGCF는 통과된 레이어의 임베딩 값들을 concat을 통해 유저와 아이템의 점수를 계산하고, LightGCN은 Layer Combination을 통해 유저와 아이템의 점수를 계산합니다. 최종적으로 계산된 점수를 통해 유저가 구매하지 않은 아이템 중 상위의 점수에 있는 k개의 아이템을 유저에게 추천합니다.
3.1.1 LightGCN
본 논문의 저자는 Embedding propagation layer에서 feature transformations과, nonlinear activation, self-connection을 제거하고 아래와 같은 새로운 Embedding propagation rule을 제안하였습니다. 이때 symmetric normalization term $\frac{1}{\sqrt{\left|N_u \right|}\sqrt{\left|N_i \right|}}$ 에서 $N_u$와 $N_i$는 각각 유저와 아이템 노드에 연결된 첫 번째 hop의 차수를 의미하는데, 컨볼루션 연산을 수행하면서 임베딩 값이 커지지 않도록 정규화 역할을 합니다.

3.1.2 Layer Combination and Model Prediction
최종적으로 유저와 아이템의 스코어를 계산하기 위한 최종 embedding 벡터의 경우 Layer의 수를 의미하는 k번째 임베딩 레이어에 $\alpha_k$를 각각 곱한 Layer combination을 통해 유저와 아이템의 최종 embedding 벡터를 구합니다. Layer combination을 수행함으로써 다음과 같은 3가지 역할을 합니다. 1) 레이어의 수가 증가할수록 임베딩 값이 서로 유사해지는 over-smoothing 문제를 해결합니다. 2) 각각의 레이어를 통과한 임베딩의 값마다 서로 다른 의미로 쓰이게 됩니다. 예를 들어 첫 번째 레이어에서는 유저와 아이템의 smoothness를 전달하고, 두 번째 레이어에서는 유저와 다른 유저가 연결된 겹치는 아이템(overlap items, overlap users)의 smoothness를 전달하고, 세 번째 레이어에서는 고차 연결성 구조에 대한 정보를 내포합니다. 3) 가중치 $\alpha $를 통해 이전에 제거했던 self-connection 효과를 갖을 수 있는데, 이는 뒷부분에서 설명하도록 하겠습니다.


3.1.3 Matrix Form
앞서 언급한 LightGCN의 수행 과정을 실제 계산을 수행하기 위한 Matrix Form 형태로 설명하면 다음과 같습니다. 먼저 유저-아이템의 interaction matrix를 $\mathbf{R} \in \mathbb{R}^{M\times N}$로 표현할 수 있으며 이때 $M$은 유저의 수, $N$은 아이템의 수를 의미합니다. 이를 유저-아이템 그래프의 인접 행렬로 표현하면 $\mathbf{A} = \begin{pmatrix}
0 & \mathbf{R} \\
\mathbf{R^T} & 0 \\
\end{pmatrix}$로 표현할 수 있습니다.(인접 행렬 : 자기 자신을 연결하는 대각노드를 기준으로 대칭 행렬 구조) 이후 K+1 번째 레이어의 임베딩은 $\mathbf{E}^{(k+1)} = (\mathbf{D^{-\frac{1}{2}}AD^{-\frac{1}{2}}})\mathbf{E}^{(k)}$ 와 같이 LightGCN의 Embedding Propagation 형태처럼 나타낼 수 있습니다. (헷갈리시는 분들은 아래의 Laplacian 매트릭스와 해당 요소들을 표현한 그림과 참고자료를 보시길 바랍니다.) 여기서 $\mathbf{D}$는 $(M+N)\times(M+N)$ 크기의 대각 차수 행렬(diagonal degree matrix)을 의미합니다.


최종 임베딩 매트릭스를 보면 초기 임베딩 값 $E^{(0)}$이 고정되어 있고 $\tilde{A}$만 제곱하여 연산의 효율성이 증가한 것을 알 수 있습니다.
3.2 Model Analysis
저자들은 다음과 같이 3가지 측면을 언급하면서 LightGCN이 단순히 불필요한 요소를 제거한 가벼운 모델이 아니라 그 이면에 있는 합리성을 입증합니다.
(1) 먼저 identity matrix($I$)를 인접행렬($A$)에 더하여 self-connection 효과를 가질 수 있는데, 이는 "Simplifying graph convolutional networks"에서 입증되었습니다. 이때 $(\mathbf{D^{-\frac{1}{2}}+I})^{-\frac{1}{2}}$ 항 같은 경우 임베딩 값들을 재조정하는 역할만 하므로 생략하였습니다. 이후 k번째 임베딩 매트릭스를 구하는 식을 이항정리를 통해 풀어서 쓸 수 있으며, 각 LightGCN 레이어의 가중합한 식과 동일합니다. ($\alpha$ 를 combination으로 표현)
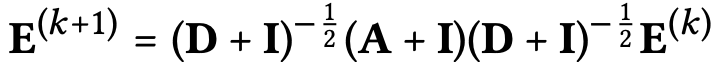

※ 이항정리 : n이 자연수일 때, $(a+b)^n$을 전개하면 $(a+b)^n = _n\rm C_0a^n + _n\rm C_1a^{n-1}b + _n\rm C_2a^{n-2}b^2 + \cdot \cdot \cdot + _n\rm C_nb^n$
(2) 다음으로 LightGCN이 over-smoothing 문제를 잘 다룰 수 있으며, 이는 "Predict then propagate: Graph neural networks meet personalized pagerank(APPNP)"에서 입증되었습니다. over-smoothing이란 레이어의 수가 증가할 수록 최종 임베딩 값이 유사해져 모델의 성능 저하를 야기하는 문제입니다. 이때 k 번째 임베딩$E^{(k)}$을 구하기 위해 초기 임베딩$E^{(0)}$ 값을 더해 줌으로써 over-smoothing 문제를 해결합니다. $\beta$를 통해 초기 임베딩 값에 대한 영향력을 조정할 수 있습니다.


(3) 마지막으로 유저(아이템)와 연결된 다른 유저(아이템)의 second-order layer를 분석하여 해당 관계의 smoothness를 구할 수 있습니다. 아래의 수식은 유저 측면에서 2-layer smoothness를 수식으로 표현하였습니다. 유저와 다른 유저들간의 공통으로 연결된 아이템으로부터 smoothness의 강도를 나타내는 coefficient를 구할 수 있습니다. 해당 식으로부터 1) 상호작용이 많은 아이템의 수가 많을수록 coefficient는 커지고 2) 해당 아이템의 연결이 적을수록 coefficient는 커지게 되며 3) 유저 $u$와 연결된 $v$가 적을수록 coefficient가 커지는 것을 알 수 있습니다.


3.3 Model Training
위의 결과를 종합할 때 LightGCN의 trainable parameters는 유저와 아이템 각각의 초기 임베딩 값이 사용됩니다($E^{(0)}$). 이후 모든 유저에 대해서 실제 구매한 아이템과 구매하지 않은 아이템의 차이를 계산하여 실제 구매한 아이템에는 높은 가중치를 부여하고 구매하지 않은 아이템에는 낮은 가중치를 부여해 loss를 계산하는 Bayesian Personalization Rank(BPR) loss를 사용하여 모델을 최적화합니다.

4. Experiments
본 논문의 저자들이 진행한 주요 실험 내용을 보도록 하겠습니다. 실험에 사용한 데이터 셋은 NGCF의 저자들과 같은 데이터를 사용하였으며, Yelp2018 데이터의 경우 개정된 버전의 데이터로 약간의 차이가 있다고 합니다.
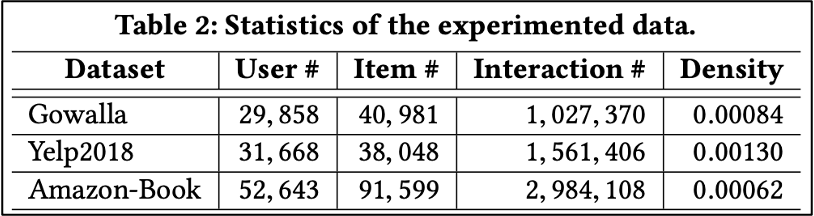
먼저 기존 NGCF 모델과 성능 비교에 대한 결과를 보면 다음과 같습니다.


해당 표를 보면 모델의 평가 지표로 recall과 ndcg를 보았을 때 모든 데이터 셋과 레이어의 수에서 LightGCN의 성능이 훨씬 우수함을 알 수 있습니다. 또한 그림의 Loss를 보게 되면 LightGCN의 Loss가 더 낮음을 볼 수 있는데, 이를 통해 NGCF 모델보다 학습을 더 잘한다는 것을 알 수 있습니다.
다음으로 최신 SOTA모델들과 비교하였을 때 역시 LightGCN이 더 우수함을 알 수 있습니다.

마지막으로 Layer combination의 효과에 대한 실험 결과로 아래의 표를 보면 LightGCN은 Layer combination을 적용하였을 때 실험 모델이고, LightGCN-single은 Layer combination을 적용하지 않고 각각의 k 번째 임베딩 레이어 $E^{k}$를 사용한 모델입니다. 먼저 주황색 막대인 LightGCN-single을 보면 Layers의 수가 증가할수록 모델의 성능이 떨어지는 것을 보아, over-smoothing이 발생했다고 판단할 수 있습니다. 반면 파란색 막대인 LightGCN의 경우 Layers의 수가 증가할수록 일관성 있게 성능이 좋아지는 것을 알 수 있습니다. 이를 통해 Layer combination의 효과로 over-smoothing 문제를 잘 해결한다고 판단 할 수 있습니다. 여기서 주목해야 할 점은 저자들이 실험한 Amazon-Book 데이터 셋에 대한 실험 결과를 보면 LightGCN-single이 over-smoothing 문제가 발생하였지만, 오히려 LightGCN 모델 보다 성능이 좋음을 알 수 있습니다. 이에 대해 저자들은 실험에서는 LightGCN의 하이퍼파라미터 $\alpha$ 를 1/k+1 으로 uniformly 하게 설정하였기 때문이며, 적절한 하이퍼파라미터 튜닝시 더 좋은 성능이 나타날 것이라고 말합니다.

5. Conclusion
결론을 정리하자면 다음과 같습니다. 본 논문의 저자는 CF에 사용하기 위한 GCN의 모델 구조는 복잡하고 불필요함을 주장하고, 이를 ablation study를 통해 증명하였습니다. 추천의 성능을 저하했던 feature transformation과 nonlinear activation을 제거하고 neighborhood aggregation과 Layer combination을 사용하여 새로운 LightGCN 모델을 제안하였습니다. 제안된 LgihtGCN 모델은 임베딩 전파 과정에서 첫 번째 레이어 $E^{(0)}$만을 학습 파라미터로 사용하여 가볍고 효율적인 모델을 만들었습니다. 또한 유저와 아이템의 스코어를 계산하기 위한 Prediction Layer에서 Layer combination을 통해 self-connection 효과를 갖고 over-smoothing을 잘 다룰 수 있었습니다.
'논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] MMGCN: Multi-modal Graph Convolution Network for Personalized Recommendation of Micro-video (0) | 2022.04.05 |
|---|---|
| [논문 리뷰] Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks (0) | 2022.02.14 |
| [논문 리뷰] Self-Attentive Sequential Recommendation (2) | 2021.11.22 |
| [논문 리뷰] Neural Collaborative Filtering (0) | 2021.09.13 |
| [논문 리뷰] Neural Graph Collaborative Filtering (0) | 2021.08.27 |



