
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Recommendation System
- collaborative filtering
- Graph Embedding
- 문장임베딩
- BERT4Rec
- 시계열 추천시스템
- 딥러닝
- UltrGCN
- Multi-Modal
- PinSAGE
- sentence BERT
- 그래프 임베딩
- DIF-SR
- sentence embedding
- 추천시스템
- graph
- 머신러닝
- Recommender System
- LightGCN
- 시퀀셜 추천시스템
- multi modal recommendation
- graph recommendation
- GCN
- VATT
- SBERT
- Sequential Recommendation
- Sequential Recommendation System
- 아마존 추천시스템
- 반복 구매
- side information
- Today
- Total
AI 공부 기록 블로그
[논문 리뷰] MMGCN: Multi-modal Graph Convolution Network for Personalized Recommendation of Micro-video 본문
[논문 리뷰] MMGCN: Multi-modal Graph Convolution Network for Personalized Recommendation of Micro-video
dhgudxor 2022. 4. 5. 16:42
본 논문은 2019년에 ACM International Conference on Multimedia에서 발표되었으며, Micro-video 데이터에 포함된 multi-modal data(시각, 음성, 텍스트 데이터)를 GCN에 적용하여 기존 추천 시스템 모델에서 좋은 성능을 보였습니다.
논문의 리뷰는 저의 주관적인 해석과 오역이 있을 수 있습니다. 이에 대해서 댓글 남겨주시면 감사하겠습니다. :)
0. Background knowledge
먼저, Multi-modal learning이란 변수의 차원이 각기 다른 데이터(modality)가 여럿이 모여 동시에 학습하는 방법을 말합니다. 주로 인간의 감정인식, 행동 인식 분야에서 활발히 연구되지만, 추천시스템에서도 다양한 modality (이미지, 텍스트, 메타데이터)가 존재하여 이를 잘 활용하게 된다면 보다 좋은 추천 성능을 나타낼 수 있을 것이라고 생각됩니다. Multi-modal의 표현 방식으로는 Joint representaion과 Coordinated representations 방법이 있습니다. 전자의 Joint representaion의 경우 각각의 modality가 서로 같은 공간으로 합쳐져서 하나의 모델을 통과시키게 되며, 수식으로는 $x_m = f(x_1, ..., x_n)$ 으로 나타냅니다. 반면, 후자의 Coordinated representations의 경우 각각의 modality마다 개별 모델을 통과하게 됩니다. 수식으로는 $f(x_1) ~ g(x_2)$으로 표현가능합니다.

1. Introduction
본 논문은 그래프를 활용하여 유저에게 새로운 아이템을 추천해 줍니다. 아래 좌측 그림에 있는 User-Item Interactions을 보았을 때, $i_1$은 $u_1$과 $u_2$가 공통으로 시청한 기록이 있습니다. $u_1$에게 새로운 영화를 추천해줄 때 $u_2$가 시청한 $i_2$ 혹은 $i_3$를 추천해줄 수 있습니다. 하지만 이때 $u_1$이 선호하는 modality(영화의 포스터, 영화의 설명)에 따라 추천되는 영화는 달라집니다. 아래 그림에서 $i_1$은 Visual Spcae에서 $i_2$와 가깝게 맵핑이 되지만, Textual Space에서는 $i_3$와 가깝게 맵핑이 됩니다. 이에 따라 $u_1$이 Visual modality와 Textual modality 중 어느 것을 더 선호하는지 구분하는 것이 중요하며 아이템에 대한 modality의 정보가 적절히 반영되어야 합니다.
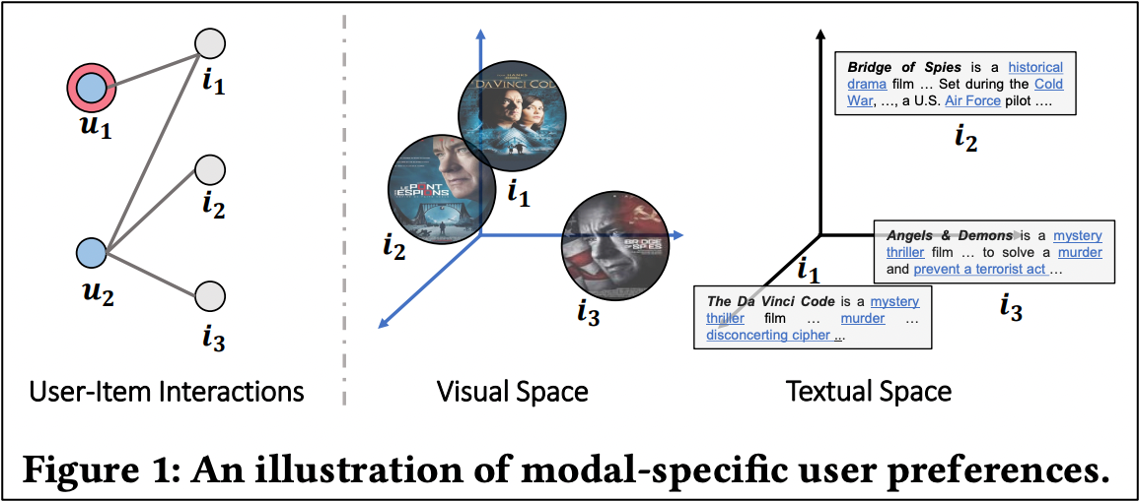
저자가 본 논문에 기여하는 3가지는 다음과 같습니다.
1) 다양한 modality의 정보 교환이 어떻게 사용자 선호도를 반영하고, 추천의 성능에 미치는 영향을 탐구합니다.
2) MGCN이라는 새로운 모델을 제안해 유저-아이템 이분형 그래프에서 각 modality의 정보가 전파되어 아이템 컨텐츠 정보를 활용한 더 나은 유저의 repsentations을 얻습니다.
3) Tiktok, Kwai, MovieLense 세 가지 데이터 셋을 활용해 최신 SOTA 모델들과 비교하여 제안 모델의 우수성을 입증하였습니다.
2. Model
전체적인 MMGCN(Multi-modal Graph Convoultion Networks)의 구조는 다음과 같으며 유저가 시청 이력이 있는 아이템의 modality를 Visual, Acoustic, Textual로 나눕니다. 각 modality 별로 이분형 그래프(bipartite graph)로 나타내고 Aggregation Layer와 Combination Layer를 통과하여 중심 노드로부터 연결된 modality의 정보를 표현할 수 있는 최종 노드를 생성합니다. 이러한 과정을 모든 modality에 대해 아이템 노드와 유저 노드를 기준으로 수행합니다. 최종적으로 유저 노드를 기준으로 합쳐진 modality와, 아이템 노드를 기준으로 합쳐진 modality가 하나의 벡터를 만들어 행렬 연산을 통해 유저에게 새로운 아이템을 추천해줍니다. 이때 각 modality마다 feautres vector로 만들어 주기 위해 Visual modality는 pre-trained ResNet50을 적용하고, Acoustic Modality는 VGGish, Textual Modality는 Sentence2Vector를 적용했다고 합니다.

이제 본 논문의 핵심 요소인 Aggregation Layer와 Combination Layer를 소개하면 다음과 같습니다. 먼저 본 논문의 Aggregation Layer는 중심 노드로부터 이웃이 되는 노드들의 정보들을 합쳐주는 역할을 합니다 $h_m = f(N_u)$. 이를 통해 중심 노드로부터 연결된 이웃 modality의 기여도를 수집할 수 있습니다. 이때 Aggregation의 방법으로는 평균을 이용하여 모든 이웃 노드들이 똑같은 기여를 한다고 가정하는 Mean Aggregation과 최댓값을 이용하여 이웃 노드 간 다양한 기여를 한다고 가정하는 Max Aggregation이 있습니다.


이때 $N_u$는 유저 노드(중심이 되는 노드)의 이웃, 즉 유저 노드(중심 노드)를 기준으로 상호작용 있는 이웃 노드를 의미합니다. 또한 $W_{1,m}$은 이웃 노드들의 정보를 얻기 위한 trainable transformation matrix를 의미하고, $j_m$은 modality $m$에 속하는 아이템을 의미합니다.
Combination Layer는 aggregation layer를 수행하여 얻은 노드의 구조적 정보 $h_m$과 유저 노드가 해당 modality에서 가지고 있었던 본래의 정보 $u_m$ 그리고 유저 노드에서 각 modal에 속하는 아이템의 연결 정보를 알려주는 $u_{id}$를 통해 하나의 통합된 representation으로 만들어 주는 역할을 합니다. 이때 각 modality의 features vector는 서로 다른 차원을 가지게 되는데, ID 임베딩 차원과 같아질 수 있도록 $W_2$ trainable weight matrix를 곱해주어 모든 modality가 같은 공간에 표현될 수 있도록 만들어 줍니다.

Combination의 방법으로는 Aggregated 된 정보와 modality의 고유 정보를 독립된 정보로 가정하고 합쳐주는 Concatenation Combination 방법과 두 정보 간 상호작용이 고려되는 Element-wise Combination 방법이 있습니다. 논문의 저자는 두 방법 중 Element-wise Combination 방법을 사용했을 때 더 좋은 성능이 나타남을 보였습니다. 아래 수식의 $w_3$는 trainable model parameters를 의미합니다.
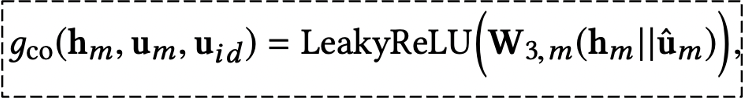

각 modality 별로 aggregation layer와 combination layer를 여러 번 쌓음으로써 유저-아이템 그래프 간의 고차연결성(high-order connectivity) 구조를 만들어 낼 수 있으며, 아이템 노드에서도 위와 유사한 방식으로 representations을 얻을 수 있습니다. modality마다 구한 representations을 합쳐서 아래와 같이 modality의 특성들이 반영한 user vector와 item vector를 구할 수 있습니다. 여기서 $u_m^{(L)}$은 $l$번째 multi-modal의 combination layer의 출력값을 의미합니다.

제안된 모델의 파라미터를 업데이트시키기 위해 추천시스템에서 흔히 사용되는 Bayesian Personalized Ranking loss를 사용하였습니다. 해당 손실함수는 실제 유저가 관찰한 아이템($i$)과 관찰하지 않은 아이템($i'$)의 차이를 계산하여 $i$와 $i'$의 점수가 극대화되도록 모델 파라미터를 업데이트시킵니다.

3. Experiments
데이터 셋은 Tiktok, Kwai, MovieLens 데이터를 사용해서 실험을 진행하였으며 Kwai 데이터 셋을 제외하고 모두 Visual, Acousitc, Textual modalities를 활용하였습니다.

저자가 제안한 모델의 성능을 비교하기 위해 사용한 Baseline 모델로는 Collaborative Filtering 기반으로 각 Modality를 적용한 VBPR, ACF 모델을 사용하였으며, 그래프 기반의 추천시스템 중 좋은 성능을 보인 GraphSAGE, NGCF 모델을 사용하였습니다. GraphSAGE, NGCF는 Multi-modal을 적용한 모델이 아니기 때문에 공평성을 위해 다음과 같은 방법을 적용하였습니다. GraphSAGE 모델 같은 경우 multi-modal features를 노드의 features로 통합하여 모델을 학습하고, NGCF는 multi-modal features를 side-information으로 간주하여 모델을 학습했습니다.(이에 대한 정확한 설명은 없지만 NGCF의 Embedding Layer에서 modality 정보를 반영했다고 판단함)
표의 결과를 보게 되면 제안 모델인 MMGCN이 가장 좋은 성능을 보인 것을 알 수 있습니다.

다음으로는 유저 5명을 랜덤 샘플링해서 다른 modality에 대해 선호도의 차이가 있는지 t-SNE를 통해 시각화하였습니다. 아래의 그림을 보게 되면 노란색으로 표현된 유저1의 경우 Visual Modality에서 뚜렷한 차이를 보이지 않고 분산되어 나타나 있지만, Textual Modality에서는 전쟁과 로맨스의 특성들로 나누어진 것을 알 수 있습니다. 마찬가지로 파란색으로 표현된 유저2의 경우 Visual Modality에서 고전주의 포스터와 애니메이션 포스터로 특성들이 나누어졌지만, Textual Modality에서는 구분된 특징을 찾을 수 없습니다. 이를 통해서 유저들이 서로 다른 modality에서 각각 다른 선호도를 갖고 있다는 것을 알 수 있습니다.
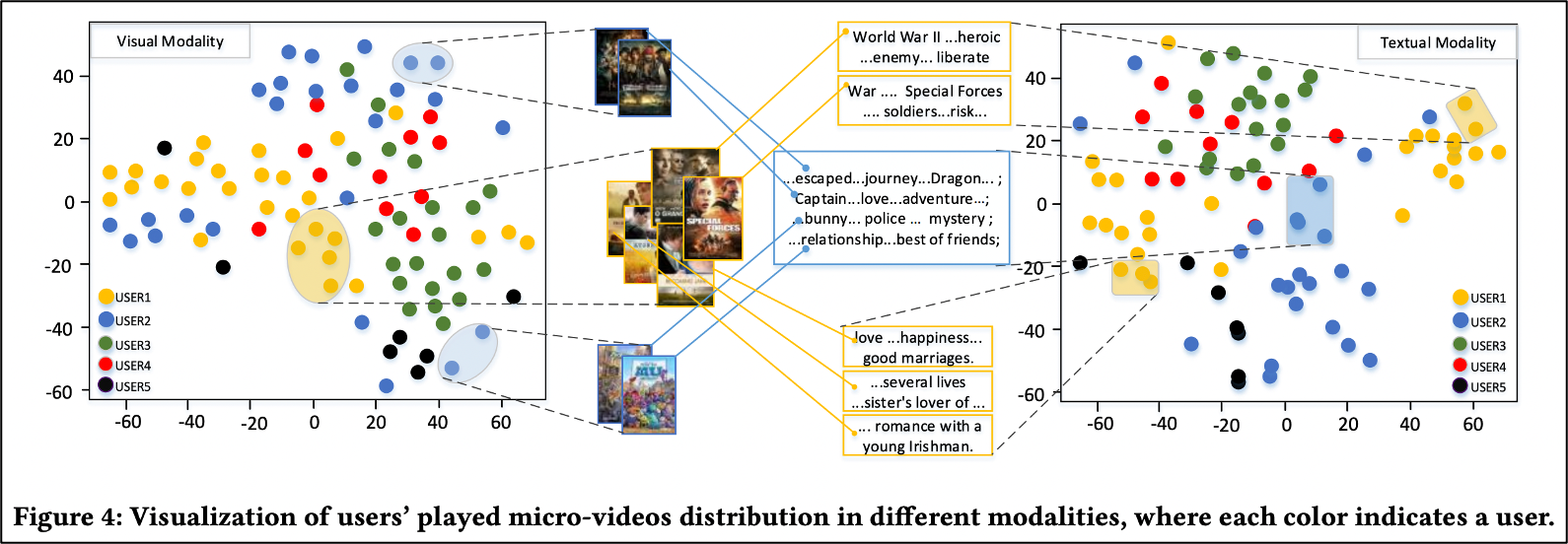
4. Conclusion
본 논문의 내용을 최종적으로 정리하면 다음과 같습니다. micro-video에서 좋은 추천을 제공하기 위해 유저와 아이템의 연결성을 고려하는 것이 중요할 뿐만 아니라 아이템 컨텐츠의 다양한 modality들을 고려하는 것이 중요하다고 주장합니다. 이에 따라서 각각의 modality의 representation을 학습하기 위해 유저-아이템 간의 그래프 구조를 활용한 MMGCN 모델을 제안하였습니다. 해당 모델의 경우 aggregation layer와 combination layer를 통해 modality의 특성들을 반영할 수 있었으며, Tiktok, Kwai, MovieLens 데이터에서 제안 모델의 우수성을 보였습니다.



